什么是高可用(HA)?
通常来说,高可用(HA, High Availability)是指系统或应用在绝大部分时间可用或按预期运行。
举个例子,D公司有班车接送员工上下班,某天早上其中一辆班车在半路上坏了,这时候司机会给车队的其他司机打电话询问他们车上是否还有空座位,如果其它车上有空的座位就可以接上这些滞留的乘客。这样就可以最大限度减少对员工上班时间的影响。

什么是vSphere HA?
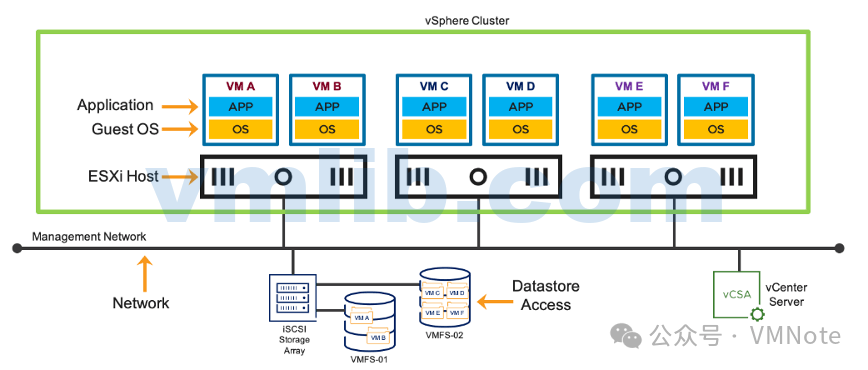
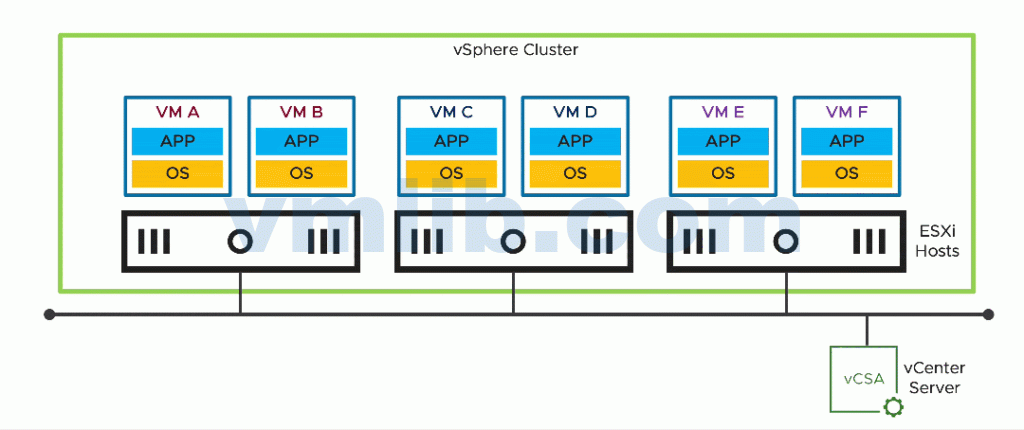
vSphere HA(高可用)是vSphere集群的一项服务功能。vSphere集群中的ESXi主机通过管理网络相互通信和协作,当集群中发生故障事件时,最大限度缩短在虚拟机(VM)上运行应用的中断(不可用)的时间,并快速恢复运行。
vSphere HA 可以保护集群中运行的应用减少以下故障带来的影响:
(1)应用软件(Application)故障
(2)虚拟机操作系统(Guest OS)故障
(3)虚拟机组件(PDL/APD Datastore)故障(4)ESXi主机处于网络隔离(Network)故障(5)ESXi主机(ESXi Host)故障
vSphere HA的工作原理是什么?
当在vSphere群集启用HA服务时,会根据特定算法自动选举其中一台ESXi主机作为Master主机(俗称首选主机),其余的ESXi主机作为Slave主机(俗称从属主机)。Master主机与vCenter Server进行通信,并监控所有受保护的虚拟机以及Slave主机的状态。Master主机发送心跳信息给Slave主机,让Slave主机知道Master的存在。集群可能会发生不同类型的主机故障,Master主机必须检测并相应地处理故障。Master主机必须能够区分故障主机与网络分区中的主机或已与网络隔离的主机。Master主机使用管理网络和数据存储检测信号确定故障的类型。当Master主机处于隔离状态或者关闭状态时,集群剩余的主机会重新选举Master主机。
类型一、应用软件发生故障
当虚拟机中运行的应用软件出现故障时,vSphere HA的默认策略会在同一台ESXi主机上重新启动虚拟机
类型二、虚拟机操作系统发生故障
当虚拟机中的客户机操作系统发生故障时,vSphere HA的默认策略会在同一台ESXi主机上重新启动虚拟机
类型三、ESXi主机发生故障
当ESXi主机发生故障的时候,该主机上运行的所有虚拟机都会发生故障。vSphere HA的默认策略会尝试在集群中的其它ESXi主机上重新启动发生故障的虚拟机。
类型四、ESXi主机管理网络发生故障
在vSphere HA 集群中,每台ESXi主机上都会运行一个名为vSphere HA Agent的代理进程。这些代理进程通过ESXi的管理网络进行通信。
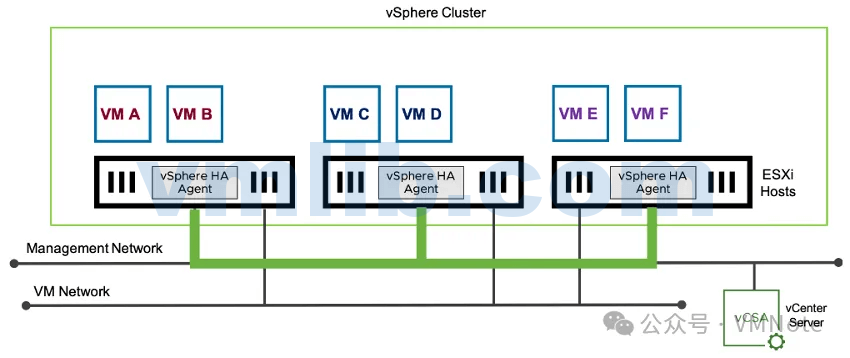
如果vSphere集群的ESXi主机没有收到某台ESXi主机代理的通信信号,那么其它ESXi主机会认为该主机已经关闭(例如关闭电源或物理硬件故障)或进入到网络隔离状态。
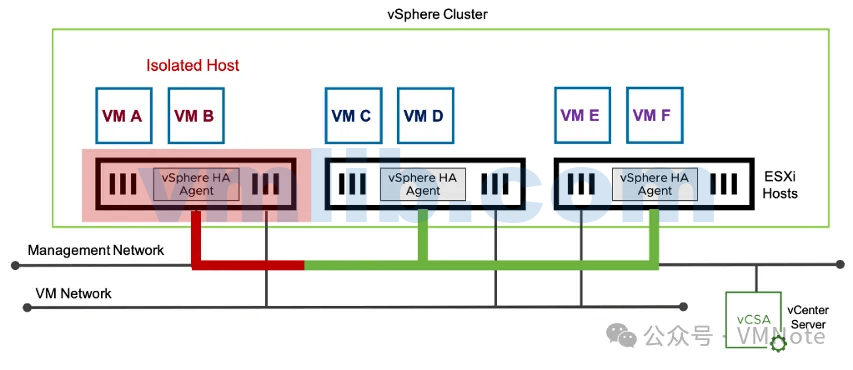
什么是ESXi主机的网络隔离?
即ESXi主机正常运行,但是由于网络问题无法与集群中的其他主机进行通信时,会将该主机视为在网络上处于隔离状态,也就是俗称孤立的主机(isolated host)如何区分ESXi主机是处于关闭还是网络隔离状态?
Master主机使用管理网络和数据存储检测信号来确定故障的类型。当一台Slave主机丢失了所有的管理网络连接,这样的Slave主机既不能联系到Master主机也不能联系到集群的其他ESXi主机时。这种情况下,Slave主机通过存储网络来通知Master,它已经是隔离状态。
vSphere HA默认策略针对处于隔离状态的ESXi主机,根据处理隔离状态ESXi上的虚拟机网络的连接情况,采取不同的响应方式
情况一、虚拟机可以访问网络
通常这种情况下,ESXi的管理网络和虚拟机的网络是处于不同的物理网络中,如果ESXi管理网络出现故障,虚拟机的网络很可能不受影响。由于虚拟机保持开启的状态且网络也能正常访问,vSphere HA不做任何响应,等待ESXi主机管理网络恢复。
情况二、虚拟机无法访问网络
ESXi和虚拟机都无法访问网络,vSphere HA会关闭虚拟机,然后在vSphere集群的其他ESXi主机上重新启动虚拟机
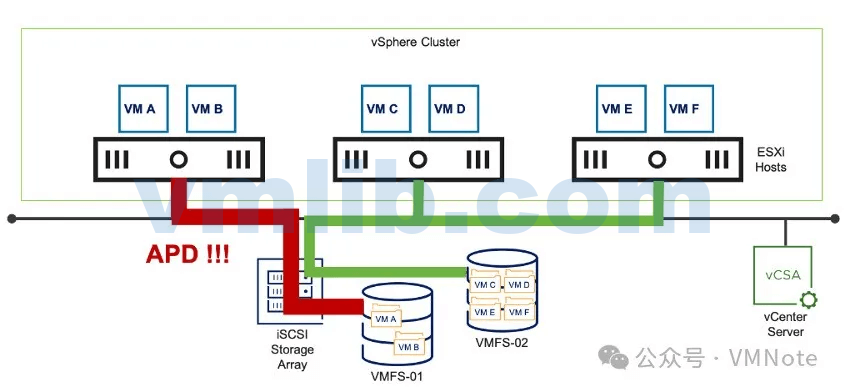
类型五、存储访问故障——全部路径中断(APD,All Paths Down)
现象:ESXi 主机无法与共享存储的存储控制器通信,不知道存储卷(存储设备)的状态,因为存储路径存在异常。例如,下图中,连接到VMFS-01数据存储的存储设备的电缆断开连接。
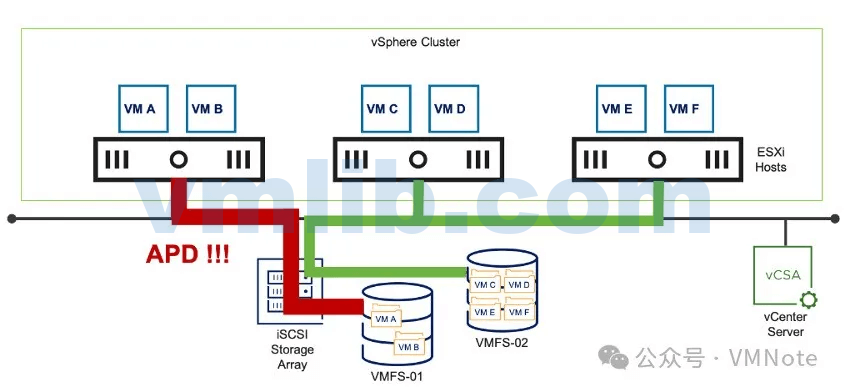
原因:交换机发生故障或存储设备线缆断开连接
结果:存储设备可能暂时不可用。
响应:vSphere HA的响应
(1)ESXi主机会等待一段时间(默认为140秒)
(2)如果存储在等待时间(默认为140秒)内恢复,ESXi主机以及其上虚拟机将继续运行,vSphere HA不做任何响应
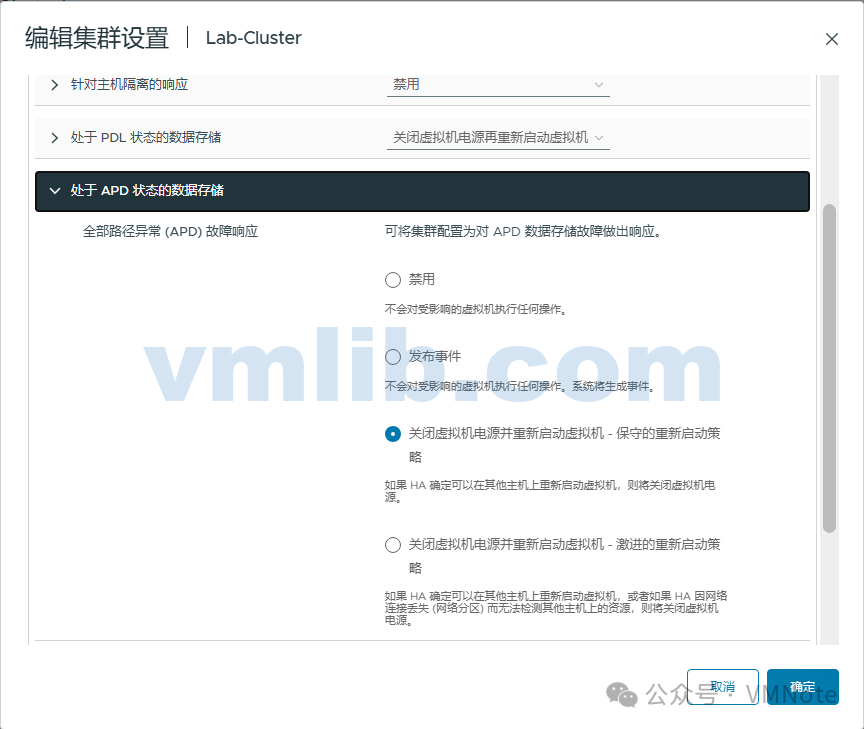
(3)如果存储未在等待时间(默认为140秒)内恢复,vSphere HA 可通过以下两种方式进行响应,具体取决于管理员的配置
- vSphere HA会触发APD事件,管理员可以在vSphere Client中查看该事件。
- 在集群中可访问虚拟机所在数据存储的主机上重新启动虚拟机。
类型六、存储访问故障——存储卷故障(PDL,Permanent Device Loss)
现象:ESXi可以正常与共享存储控制器通信,但是被告之存储卷(存储设备)无法访问,处于丢失状态。例如,VMFS-01 所在的存储设备发生 PDL 情况
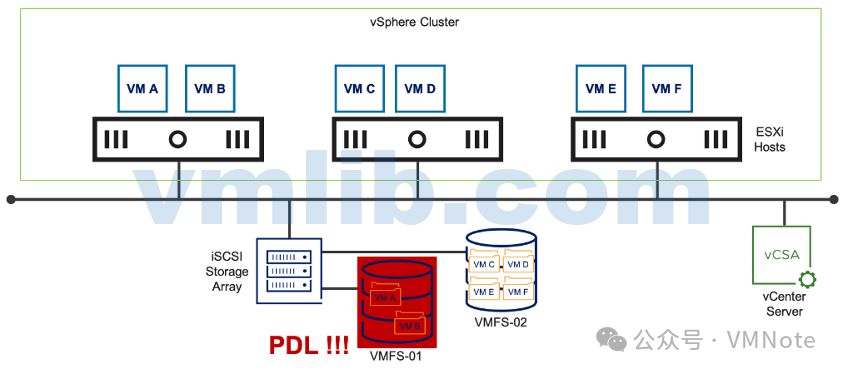
原因:存储设备(例如:硬盘)遭到意外移除,或者存储设备遇到不可恢复的硬件错误。
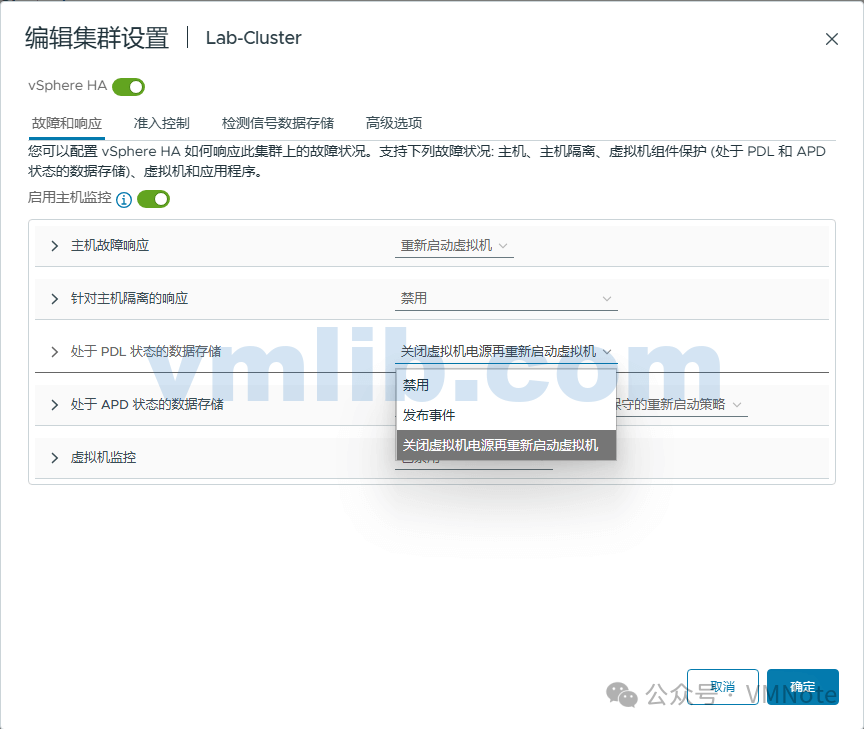
结果:存储控制器确定存储卷(存储设备)永久不可用,并通知 ESXi 已发生 PDL 情况。vSphere HA 可通过以下两种方式进行响应,具体取决于管理员的配置
- 生成 PDL 事件,管理员可以在 vSphere Client 中查看该事件。
- 关闭虚拟机,并尝试在集群中可访问虚拟机数据存储的主机上重新启动虚拟机。
那么,问题来了,ESXi主机怎么知道当前的存储访问故障是属于APD还是PDL呢?
PDL事件,是由存储控制器直接告诉ESXi主机,APD是ESXi自己访问不到存储卷,且也没收到存储控制器的PDL通知,且其他ESXi主机可以正常访问该存储卷。
为了增强vSphere HA在ESXi集群中的高可用性,管理员应深入理解其工作原理,并根据实际环境配置最佳策略。通过有效地处理虚拟机故障、ESXi主机故障、存储故障及网络隔离问题,vSphere HA能够确保虚拟化环境的稳定性和高效性。在配置vSphere HA时,合理设置故障恢复策略、调整虚拟机重启优先级,并密切监控故障事件,可以显著提高企业IT基础设施的容错能力。如果你正在寻找更深入的vSphere HA配置与故障处理方案,了解这些细节将为你的虚拟化环境带来更高的可靠性和可用性。


 VM技术助理
VM技术助理