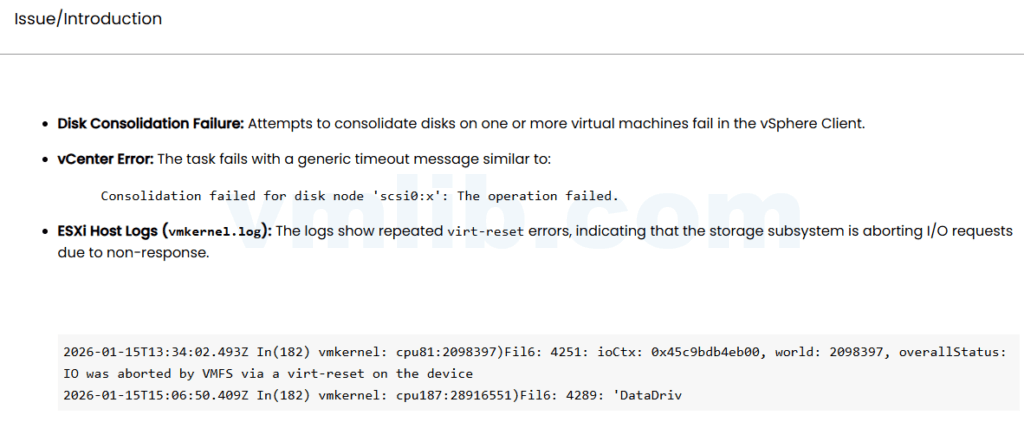
在ESXi 8.x环境中,如果你遇到磁盘合并操作失败,并且在vCenter中看到类似\”Consolidation failed for disk node ‘scsi0:x’: The operation failed\”的错误信息,同时在ESXi主机的vmkernel.log中发现virt-reset相关错误,那么你可能正在遭遇一个比较复杂的问题。
其实呢,这个问题的根源通常与光纤通道网络有关。它是由光纤通道拥塞扩散(通常称为”Slow Drain”或”Credit Stall”)引起的。即使受影响的虚拟机没有通过ISL进行复制,它也会受到交换机范围内的资源竞争影响。
具体来说,故障的发生过程是这样的:首先,某个ISL端口(例如Port 15)出现物理错误(如SFP/电缆损坏),导致它丢弃帧或无法返回缓冲区信用。然后,该链路的交换机内部内存缓冲区会因为无法传输帧而填满。由于交换机缓冲区通常是共享资源,内存不足会扩散到同一交换机上的其他端口,包括连接到本地ESXi主机的端口。最后,ESXi主机尝试写入数据(磁盘合并)时,交换机会因为缓冲区已满而延迟请求,延迟超过SCSI超时阈值(通常30秒),导致主机中止命令(virt-reset)。
直接开干,解决这个磁盘合并失败问题的方法是清除存储网络拥塞。以下是具体步骤:
步骤1:识别故障链路
首先,你需要查看SAN交换机日志,查找显示高错误计数(CRC、帧丢失或信用丢失)的端口。在这种情况下,连接站点的ISL端口通常是根本原因。
步骤2:隔离故障链路(临时解决方法)
⚠️ 警告:在执行此步骤之前,请先验证冗余性。如果故障ISL是站点之间的唯一链路,禁用它将切断连接并停止所有复制。
1. 暂停复制:暂停存储阵列上的所有活动复制会话,以防止队列积压。
2. 禁用端口:在交换机上管理性禁用(关闭)故障的ISL端口。
3. 效果:这将停止错误的积累并清除”信用饥饿”,立即消除交换机的背压。
步骤3:重试磁盘合并
一旦端口被禁用并且背压已清除,在vSphere中重试磁盘合并操作。它现在应该能够成功完成。
步骤4:恢复冗余(如果适用)或安排维修
- 如果存在冗余,保持坏链路禁用直到修复。
- 如果没有冗余,重新启用链路以恢复DR保护,但安排维护窗口以更换物理组件(SFP收发器和光纤电缆)。
验证和检查命令
在解决问题过程中,你可以使用以下命令来帮助诊断和验证:
1. 检查ESXi主机的存储路径状态:
esxcli storage core path list2. 查看磁盘设备信息:
esxcli storage core device list3. 检查存储适配器状态:
esxcli storage san fc list4. 查看详细的vmkernel日志:
tail -f /var/run/log/vmkernel.log通过这些步骤,你应该能够成功解决ESXi 8.x中的磁盘合并失败问题。需要注意的是,这个问题的解决通常需要SAN网络管理员的配合,因为需要检查和操作光纤通道交换机。


 VM技术助理
VM技术助理