问题现象:vMotion极慢、超时失败、日志提示timeout / keepalive 断开
在使用VMware vSphere或VMware ESXi集群做虚拟机迁移时,正常情况vMotion带宽应能跑满5–10Gbps 网络,迁移几十GB内存的虚拟机通常只需几十秒。
但有些环境中会出现非常反常的情况:从 ESXi-A 迁移到 ESXi-B 时速度极慢,带宽只有几百KB/s到 1MB/s,最终迁移超时失败,而反方向(B → A)却完全正常。
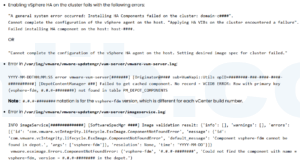
vmkernel.log 里通常可以看到类似报错:
failed to read stream keepalive: Connection closed by remote host
Migration considered a failure by the VMX
VMotion bandwidth in last 1s: 440 KB/s, 10s: 1 MB/s
表现特征也很典型:
- vMotion 长时间卡在 10% / 14% / 21%
- 迁移数分钟仍未完成
- 最终 timeout 失败
- 只有单向迁移异常
- 切换到另一块 vmnic 后立即恢复正常
这种“网络能通但速度极慢”的问题,最容易被误判成 CPU、存储或资源瓶颈,但真正原因大几率往往在 vMotion网络本身。
根本原因:vMotion网络链路存在丢包,触发 TCP 重传
从原理上讲,vMotion迁移本质是大规模内存数据通过TCP持续传输,对延迟和丢包非常敏感。哪怕 0.1% 的 packet loss,都可能导致吞吐量断崖式下降。根据排查经验以及官方说明,这类问题通常是:
👉 vMotion 源 ESXi 发出的数据包,目标 ESXi 没有收到
👉 TCP 不断重传(retransmission)
👉 带宽剧烈波动
👉 keepalive 超时
👉 最终迁移失败
抓包时可以看到:
- Source 发包正常
- Destination 丢失部分包
- TCP Retransmission 激增
- Throughput 上不去
尤其当问题只发生在某一块 vmnic(例如 vmnic-A),而切换到 vmnic-B 后恢复正常时,基本可以锁定是 物理链路层问题,而不是 vMotion 配置或 ESXi 软件 Bug。
排查思路:从逻辑到物理逐层验证
实际运维中一般来说,可以建议按这个顺序排查:
先确认是否单向问题(A→B 慢,B→A 正常),如果是,大概率是源端链路异常。
然后在迁移过程中分别在两台ESXi做packet capture抓包,对比发送与接收包数是否一致。接着尝试把 vMotion vmkernel绑定到另一块vmnic,如果速度立即恢复,说明问题集中在原网卡或光链路。
进一步可以:
- 更换 SFP/GBIC 光模块
- 更换光纤跳线
- 更换交换机端口
- 交换 vmnic-A / vmnic-B 物理连接
- 查看 NIC error / drop / CRC 统计
如果更换光模块和光纤后恢复正常,说明是光链路故障;如果仍异常,则可能是该 vmnic 硬件老化或接口损坏。

一些解决方案与运维建议
在问题未彻底修复前,可以先把 DRS调为 Manual,避免自动vMotion频繁失败影响业务。
最终解决通常是更换有问题的光模块、网线或物理网卡。经验上看,绝大多数vMotion慢速或timeout迁移失败问题,80%都和物理网络丢包有关,而不是ESXi配置错误。
如果你在搜索:
- vMotion 很慢 1MB/s
- vMotion timeout 失败
- vmkernel.log keepalive failed
- ESXi packet drop
- vMotion 迁移卡住
- vmnic 丢包 / 光模块故障
基本都可以优先从网络丢包和硬件链路入手排查。
记住一句话:vMotion 对丢包极度敏感,只要有 packet loss,迁移一定慢甚至失败。


 VM技术助理
VM技术助理